If you're new to machine learning, two words show up early and often: classification and regression. They sound technical, but the idea behind each is simple. Machine learning is mostly about getting a computer to learn patterns from data instead of being handed every rule by a programmer. Classification and regression are two of the most common things you can ask it to learn. Here's how they differ, and how to tell which one your problem actually needs.
First, supervised learning
Both classification and regression sit under the same umbrella: supervised learning.
In supervised learning, the data you train on already comes with the answers attached. Those answers are called labels. Picture a stack of flashcards. One side has the question, which is your data, and the other side has the correct answer, which is the label. The model studies enough of these pairs to learn the link between the two, so when it later sees new data with no label, it can fill in a sensible answer on its own.
Classification and regression are the two jobs people reach for most once they're working with labeled data.
What classification does
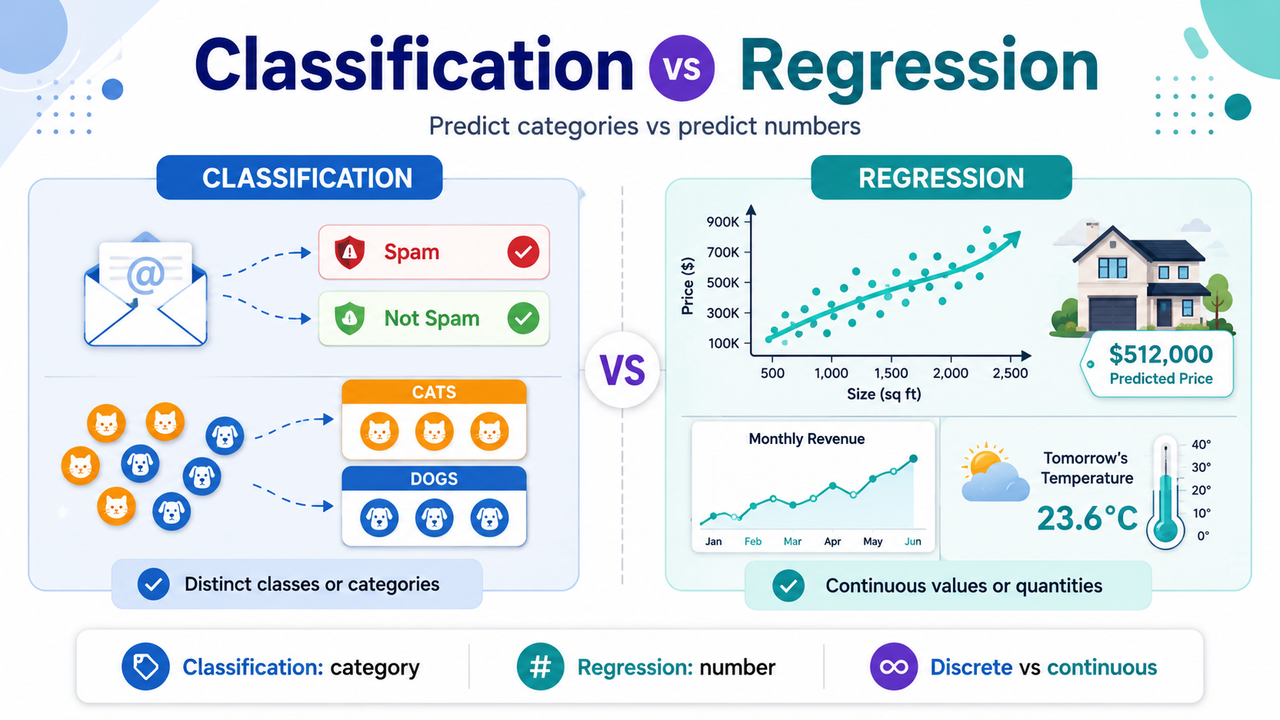
Classification predicts which category something belongs to. If the answer to your problem is a label or a group rather than a number, it's a classification problem.
The classic example is a spam filter. You train it on a pile of emails that are already marked spam or not spam, and it learns to drop new emails into one of those two boxes.
What regression does
Regression predicts a number. If the answer can land anywhere on a scale, you're doing regression.
House and car prices are the standard example. You feed the model lots of past sales, each one described by features like age, mileage, and location, along with the actual price it sold for. From enough of those, it learns to estimate a price for a house it has never seen.
Discrete answers vs continuous ones
The quickest way to tell the two apart is to look at the kind of answer they hand back.
Classification gives you discrete answers: separate, countable categories. A photo is a cat or a dog. An email is spam or it isn't. Nothing sits between the buckets.
Regression gives you continuous answers, a number that can sit anywhere on a scale. A model might price a house at $250,000, or $250,001, or $250,001.50. The gradations never really stop.
A few real examples
Classification shows up whenever the goal is to sort things into named groups. A spam filter marks mail as safe or junk. A medical model can scan a brain image and flag whether a region looks like a tumor. A moderation system can tag news articles by topic or hide comments that break the rules.
Regression shows up whenever the goal is to land on a number. Real estate models estimate what a home is worth from past sales nearby. Finance teams forecast next year's revenue off this year's figures. A weather model predicts tomorrow's high in degrees.
The algorithms behind each
Different problems call for different algorithms, and there's some overlap between the two.
For regression, people often start with linear regression, then reach for decision trees and random forests when the data gets messier.
For classification, decision trees and random forests turn up again. The one that trips up beginners is logistic regression. The name says regression, but it's a classification algorithm. It works out the probability that something belongs to a class, say a 20 percent chance an email is spam, and uses that probability to pick a label.
Which one does your problem need?
Ask what you'll do with the answer.
Say you're estimating house prices. If the rest of your system needs the actual dollar figure, frame it as regression. But if you only ever turn that price into a band like cheap, mid, or pricey, and the exact number never matters, you're better off treating it as classification from the start.
Quick comparison
Classification | Regression | |
|---|---|---|
Goal | Predict a category | Predict a number |
Answer type | Discrete buckets | Continuous scale |
Examples | Spam detection, tumor flagging | House prices, revenue forecasts |
Typical algorithms | Logistic regression, decision trees | Linear regression, random forests |
The short version
Sorting things into buckets is classification. Predicting a specific number is regression. Once that one distinction clicks, a lot of supervised learning starts to fall into place.
Discussion
Responses(1)
excellent explaination bravoo .